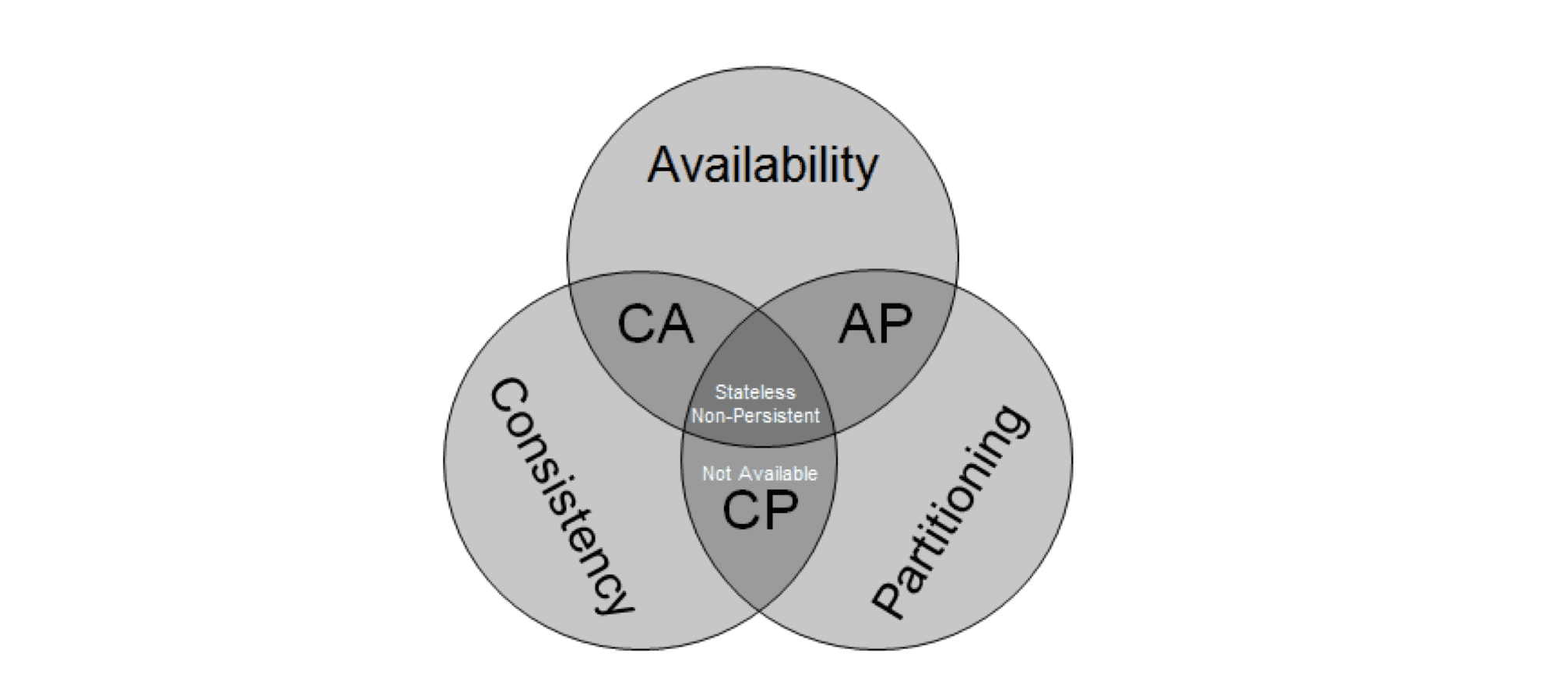
CAP 이론은 분산 시스템에서는 데이터 일관성(data consistency), 시스템 가용성(system availability), 네트워크 분할 허용성(network to partition-tolerance) 간의 고유한 균형이 존재하는데, 이들 세 특성 가운데 두 가지를 제공할 수 있지만, 세 가지 모두는 제공하지 않는다는 정리입니다. 그중 앞글자만 따서 CAP 라고 호칭 합니다.
우선 각각의 특성을 살펴 보겠습니다.
- 모든 노드가 같은 시간에 같은 데이터를 볼수 있는것을 의미합니다.
- 만약 최신 데이터가 아니라면 에러를 돌려줘야 합니다.
- 분산환경에서 가장 구현이 어려운 개념입니다.
- 모든 클라이언트가 읽고 쓸수 있어야 합니다. 즉 몇개의 노드가 죽어도 항상 시스템이 응답 가능한 상태를 뜻합니다.
- 가용성을 보장한다는 말은 이전 데이터를 볼수도 있다는 말입니다.
- 분단 내성(Partition tolerance) :
- 데이터가 분산 환경에 나누어져 있는 환경에서도 잘 동작하는 것을 의미합니다.
마이크로 서비스는 분산 환경에서 작동하기 때문에 항상 P 를 만족해야 합니다. 이러한 상황에서 일관성(Consistency) 을 선택 할 것이냐, 가용성(Availability) 을 선택해야 합니다.
CP 시스템 : 쇼핑몰 예제에서 주문을 할때 재고량이 항상 일치를 해야한다면, 일관성(Consistency)을 유지하는 방법입니다. 즉 주문 서비스와 상품 서비스가 항상 데이터가 일치 해야 합니다. 만약 10개의 서비스가 기동중이라면 10개중 1개라도 문제가 있으면 에러를 뱉어야 하고, 실패 처리를 해야합니다. 서비스가 많아질수록 모든 데이터를 동기화 하는데 시간이 오래 걸립니다. 이는 성능과 가용성에 심각하게 악영향을 끼칩니다.
AP 시스템 : 항상 응답하는 시스템을 만들기 위해서, (심지어 네트워크가 끊어져도) 기본값을 설정해주면 됩니다. 예를들어 주문을 하려고 할때 상품 시스템이 죽어있어도, 이전에 조회 해 놓았던 데이터를 보여주면 가용성은 만족됩니다. 이는 성능은 높아지지만 이전데이터를 볼수도 있고, 심지어 문제가 발생한지도 모를 수 있습니다.
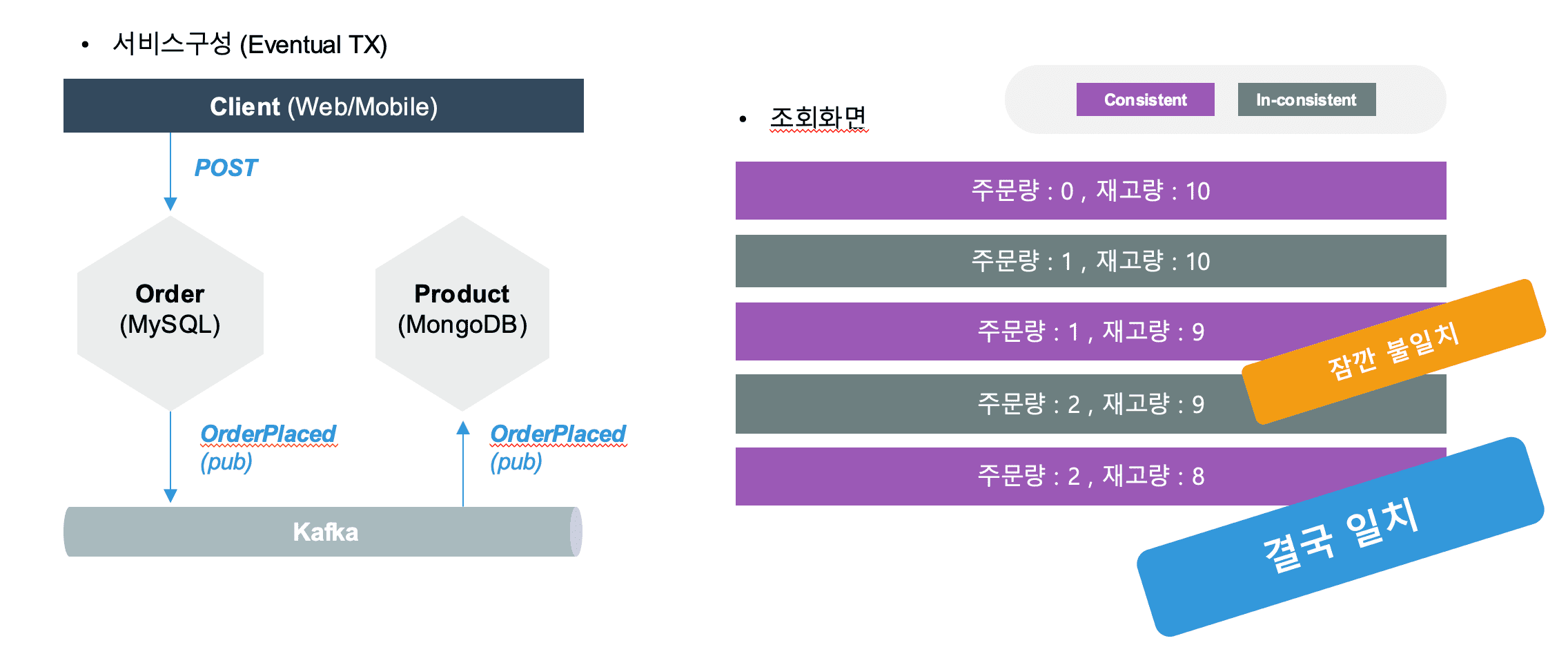
이러한 상황에서 최종 일관성 (Eventual Consistency) 은 A + P 를 만족하는 상황에서 결론적으로 C 를 만족하는 방법입니다.
이것은 순간적으로 과거의 상황을 볼 수 있지만, 결국은 일관성이 마추어 집니다.
이벤트 드리븐 방법은 이벤트 큐/메세지 시스템 (예: kafka ) 이 데이터의 원천 역할을 합니다. 서비스에서 이벤트를 조금 늦게 받을수는 있어도, 결국에는 모든 이벤트를 수신하여 처리를 하는 방식이기에 최종 일관성을 유지시켜서 시스템을 구현 할 수 있는 방법입니다.
Saga 패턴
분산 트랜잭션 중에 가장 널리 알려진 패턴이 Saga 패턴입니다.
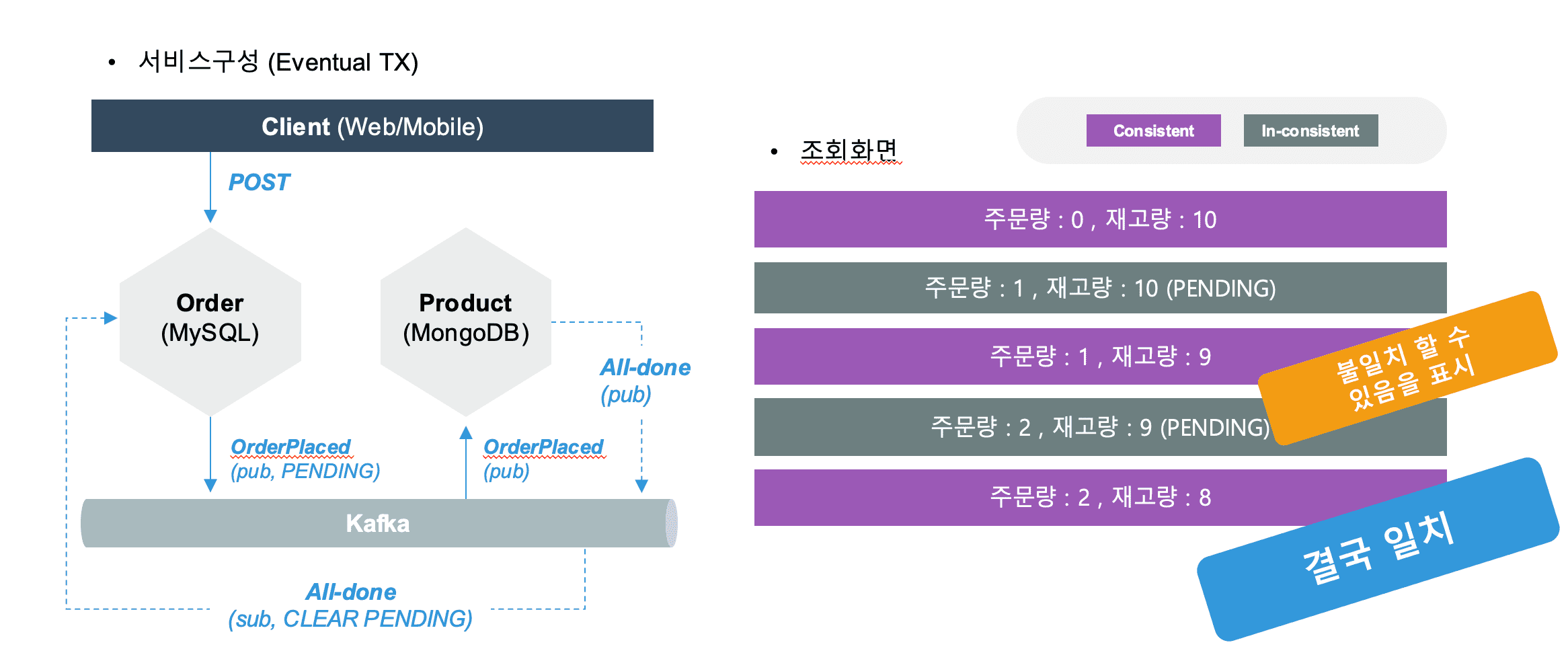
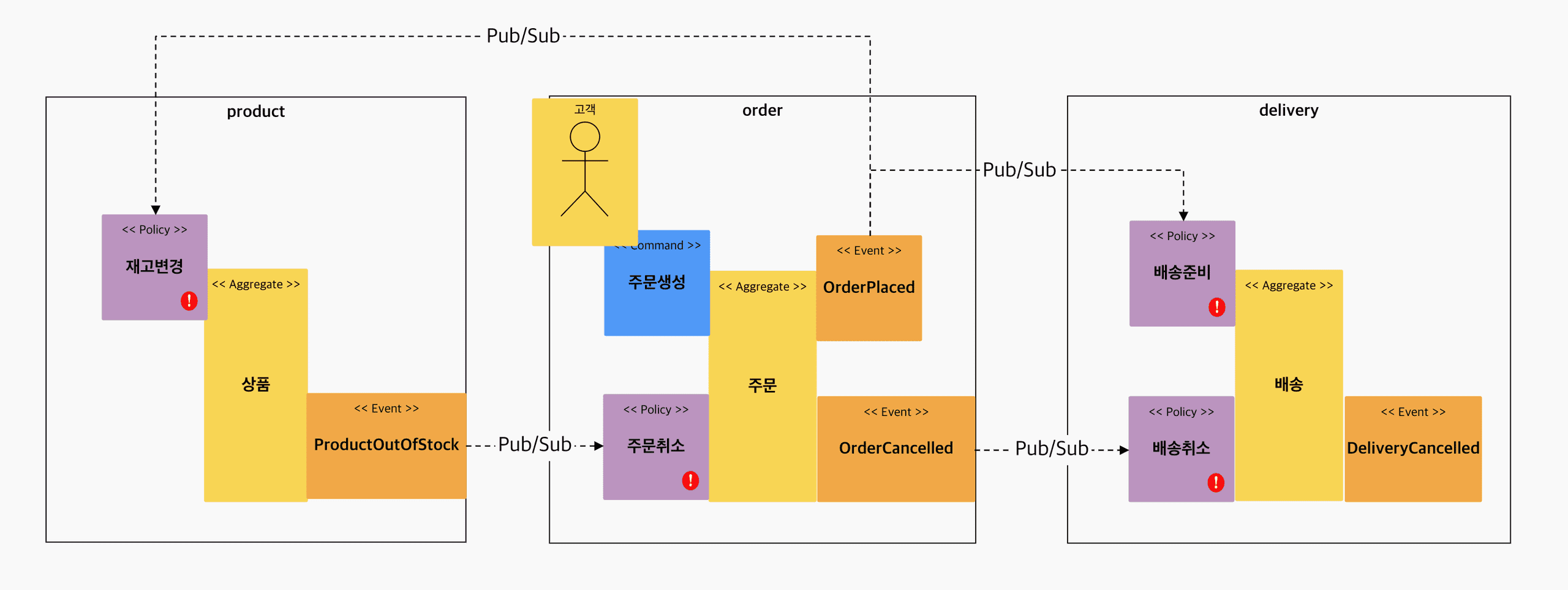
Saga 패턴은 각 서비스의 트랜잭션은 단일 서비스 내의 데이터를 갱신하는 일종의 로컬 트랜잭션 방법이고, 첫번째 서비스의 트랜잭션이 완료 후에 두번째 서비스가 트리거 되어, 트랜잭션을 실행하는 방법입니다. 예를들어 주문 서비스에서 주문 처리가 완료 되고, OrderPlaced 라는 이벤트가 발행되면, 상품서비스나 배송 서비스에서 OrderPlaced 이벤트에 반응하여 각자의 데이터를 변경시키는 방법 입니다.
Saga 패턴은 2PC 의 단점을 보완하여 줍니다. 2PC는 하나의 트랜잭션으로 묶어서 처리를 하는 방식이지만, 마이크로 서비스 환경에서는 모든 요청이 api 만으로 통신이 안되기 때문에 실제로는 구현이 어렵습니다.
Saga 패턴은 데이터의 원자성(Atomicity) 을 보장해 주지 않습니다. 이는 각각의 서비스에서 개별 데이터 베이스를 허용하여 DBMS polyglot 구성을 허용하였기 때문입니다. 그렇기에 일관성을 달성하기 위해서는 프로세스 수행 과정상 누락되는 작업이 없는지 면밀히 살펴야하며, 실패할경우 에러 복구를 위한 보상 트랜잭션 처리 누락이 없도록 설계해야합니다.
Saga 패턴의 종류는 Choreography 방식과 Orchestration 방식이 있습니다. 이벤트 드리븐과 마이크로 서비스에서 조금더 적합한 방식은 Choreography 방식 입니다.
- Choreography 방식은 Event 방식으로 비동기로 작동하는 방식입니다. 각각의 서비스는 이벤트를 발행하고, 트리거링 하여 개별적으로 동작을 하는 방식입니다.
- 장점
- 간단하고 구축하기 쉽습니다.
- 단점
- 어떤 서비스가 어떤 이벤트를 수신하는지 추측하기 어렵습니다.
- 트랜잭션이 많은 서비스를 거쳐야 할 때 현재 상태를 인지하기 어렵습니다.
- Orchestration 방식은 Command 방식으로 메니저 서비스(Orchestrator) 가 존재하여 어떤일을 해야 할지 명령을 내리고, 완료 되었을시 끝났다고 알려주는 방식입니다.
- 장점
- 서비스간의 종속성이 없고 Orchestrator가 호출하기 때문에 분산트랜잭션의 중앙 집중화가 됩니다.
- 서비스의 복잡성이 줄어 구현 및 테스트가 쉽습니다.
- 롤백을 쉽게 관리할 수 있습니다.
- 단점
- 모든 트랜잭션을 Orchestrator가 관리하기 때문에 로직이 복잡해 질 수 있습니다.
- Orchestrator라는 추가 서비스가 들어가고 이를 관리해야 합니다.
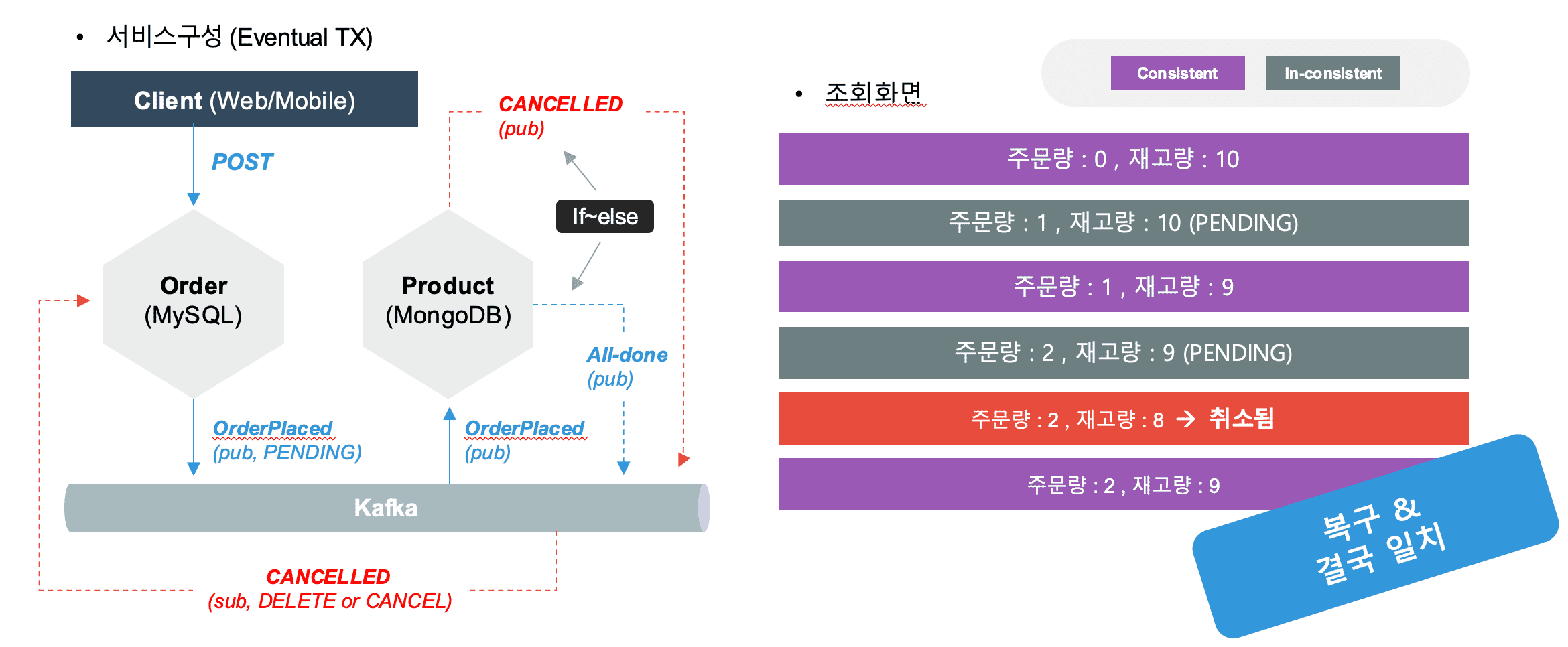
Saga Roll-Back 구성
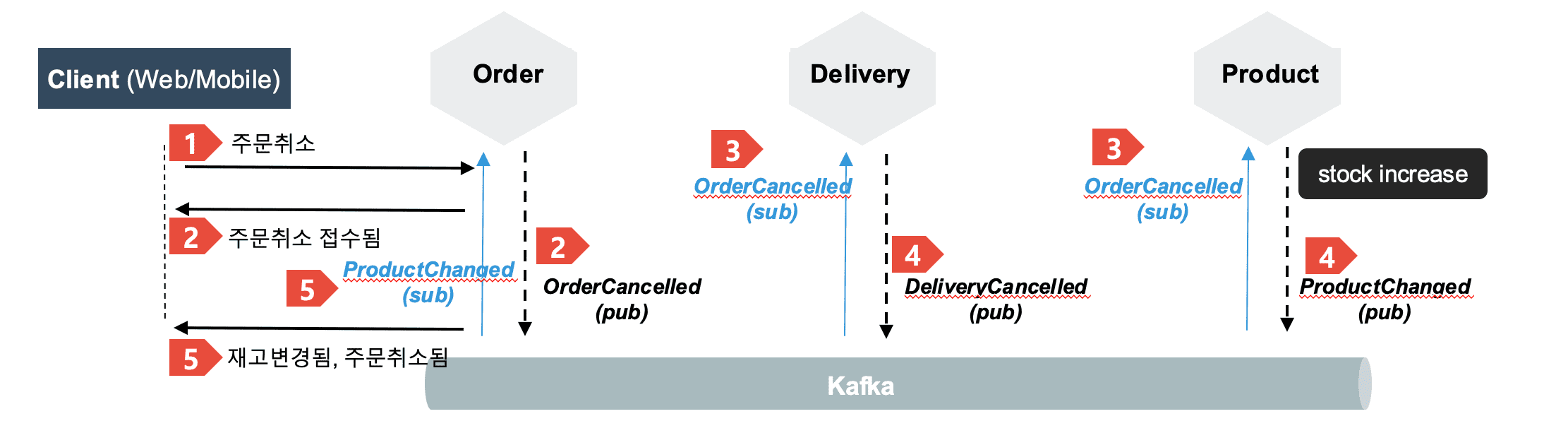
위 그림은 Saga 패턴중 Choreography 방식으로 보상 트랜잭션을 구성하는 방법입니다.
상품 서비스에서 트랜잭션 실패로 트랜잭션을 롤백해야 할때 CANCELLED 라는 이벤트를 발생시켜 주문 서비스에서 CANCELLED라는 이벤트를 트리거링 하여 주문 취소 로직을 실행 시키면 됩니다.
주문 서비스를 설계 할때 에러가 났을때 주문 취소는 어떤 방식으로 처리를 할지를 고려해야 합니다.
이벤트 드리븐의 보상 트랜잭션에 대한 말이 나올때 가장 많이 나오는 질문은, ‘에러가 났을때 상황을 미리 정의해서 구현을 해야 한다면, 개발 비용이 늘어나는것 아닌가요?’ 라는 질문입니다. 하지만 반대로 생각해보면, 에러가 나는 상황은 사용자의 변심이나 실수로 언제든지 발생 하는 일입니다. 예를 들어, 주문이 이루어 졌을때, 트랜잭션중 에러가 발생을 하면 주문을 취소 해야 합니다. 주문을 취소하는 것은 사용자가 버튼으로 취소를 할 수도 있고, 시스템에서 재고가 없어서 취소를 할 수도 있습니다. 즉 어차피 구현을 해야하는 로직입니다.
어차피 구현 되었어야 하는 주문 취소라는 로직을 에러가 났을때 연결하여 처리를 하면 됩니다.
최종 트랜잭션 & Saga 구현 실습
원할한 실습을 위하여 소스코드가 구현된 서비스를 가져와서 작업을 하겠습니다. 아래 git clone 명령어를 실행하여 주문,배송,상품 서비스의 코드를 로컬환경에 셋팅 합니다.
mkdir saga-rollback
cd saga-rollback
git clone https://github.com/event-storming/orders.git
git clone https://github.com/event-storming/products.git
git clone https://github.com/event-storming/delivery.git
실습에 앞서서 세개의 프로젝트를 구동 합니다. 이벤트 드리븐 시스템이기 때문에 localhost:9092 로 kafka 가 실행 되어져야 합니다.
카프카 설치 및 실행 참고
- 서비스 기동
- 각각의 폴더로 들어가서 서비스를 실행합니다.
cd orders
mvn spring-boot:run
- products 와 delivery 도 실행을 합니다.
- 기동 확인
-
상품 서비스
http http://localhost:8085/products
-
주문 서비스
http http://localhost:8081/orders
-
배송 서비스
http http://localhost:8082/deliveries
-
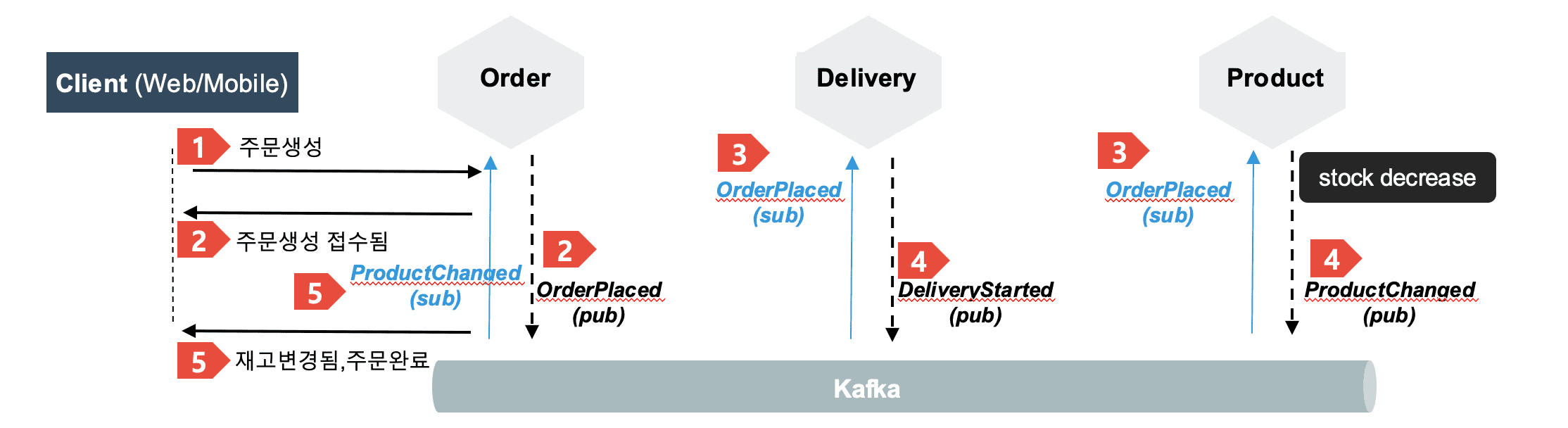
위의 3개의 프로젝트는 기본적인 Saga 패턴이 적용 되어있습니다. 사용자가 주문을 하였을때 상품 서비스의 재고량이 줄어들고, 사용자가 주문을 취소 하였을때, 상품 서비스의 재고량이 늘어나도록 트랜젝션이 묶여 있습니다.
사용자가 주문을 할 때
- 주문서비스의 OrderCancelled 와 배송서비스의 DeliveryCancelled 라는 이벤트는 이미 존재 합니다.
- 그러면 해야할 작업은 상품 서비스에서 OrderPlaced 이벤트가 왔을때, 재고량 체크를 하여 재고량이 없을시 ProductOutOfStock 이벤트를 발행 하면 됩니다.
- 주문 서비스에서 ProductOutOfStock 이벤트를 수신하여 OrderCancelled 이벤트를 발행하도록 구현하면 됩니다.
- 현재 주문 서비스에서 재고량을 체크 하도록 샘플은 구현이 되어있습니다. 주문서비스의 Order.java 파일을 열어서 throw new OrderException(“No Available stock!”); 라고 설정되어있는 부분을 주석 처리 합니다. (2개)
order 프로젝트 > Order.java
@PrePersist
private void orderCheck(){
...
if("true".equalsIgnoreCase(env.getProperty("checkStock"))){
// 1. 주문에 대한 상품 조회 - API
...
if( jsonObject.get("stock").getAsInt() < getQuantity()){
// throw new OrderException("No Available stock!");
}
}else{
...
if( product.getStock() < getQuantity()){
// throw new OrderException("No Available stock!");
}
}
...
}
- 상품 서비스에서 ProductOutOfStock 이벤트를 생성합니다.
- 간단하게 상품아이디와 주문아이디만 받아서 넘기는 작업을 하겠습니다.
products 프로젝트 > ProductOutOfStock.java
public class ProductOutOfStock extends AbstractEvent {
private String stateMessage = "재고량 바닥";
private Long productId;
private Long orderId;
public ProductOutOfStock(){
super();
}
public String getStateMessage() {
return stateMessage;
}
public void setStateMessage(String stateMessage) {
this.stateMessage = stateMessage;
}
public Long getProductId() {
return productId;
}
public void setProductId(Long productId) {
this.productId = productId;
}
public Long getOrderId() {
return orderId;
}
public void setOrderId(Long orderId) {
this.orderId = orderId;
}
}
- 상품 서비스에서 재고량이 없는 경우 ProductOutOfStock 이벤트를 발행하도록 구현합니다.
- ProductService.java 의 @StreamListener 부분에 아래처럼 변경
products 프로젝트 > ProductService.java 파일의 기존 코드
/**
* 주문이 발생시, 수량을 줄인다.
*/
if( orderPlaced.isMe()){
Optional<Product> productOptional = productRepository.findById(orderPlaced.getProductId());
Product product = productOptional.get();
product.setStock(product.getStock() - orderPlaced.getQuantity());
productRepository.save(product);
}
products 프로젝트 > ProductService.java 파일의 변경 코드
/**
* 주문이 발생시, 수량을 줄인다.
*/
if( orderPlaced.isMe()){
Optional<Product> productOptional = productRepository.findById(orderPlaced.getProductId());
Product product = productOptional.get();
product.setStock(product.getStock() - orderPlaced.getQuantity());
if( product.getStock() < 0 ){
System.out.println("productOutOfStock 이벤트 발생");
ProductOutOfStock productOutOfStock = new ProductOutOfStock();
productOutOfStock.setProductId(orderPlaced.getProductId());
productOutOfStock.setOrderId(orderPlaced.getOrderId());
productOutOfStock.publish();
}else{
productRepository.save(product);
}
}
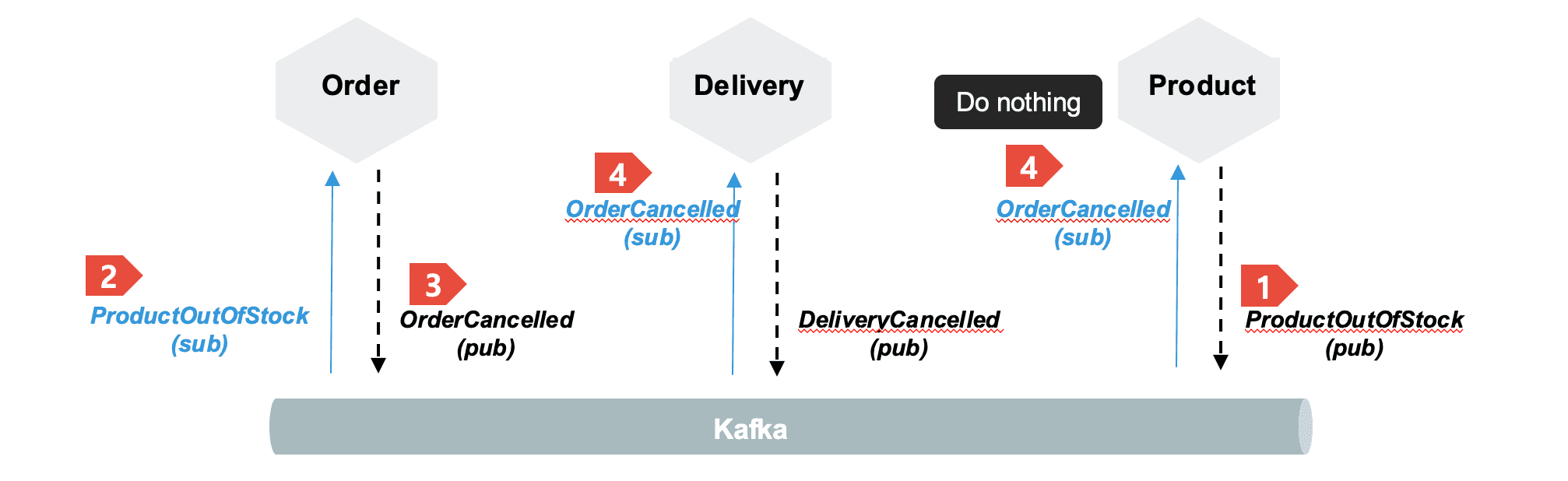
- 여기까지 작업시 주문발생 하였을때, 상품서비스의 재고량이 없다면 ProductOutOfStock 이벤트가 발행됩니다.
- 주문서비스에서 ProductOutOfStock 이벤트를 수신하여 주문을 취소하는 로직을 작성합니다.
-
ProductOutOfStock 이벤트를 주문서비스에서 받아야 하니, 상품서비스의 ProductOutOfStock.java 파일을 복사하여 주문서비스에 붙여넣기 합니다.
-
이벤트를 수신하는 OrderService.java 파일에서 아래와 같이 StreamListener 를 추가합니다.
order 프로젝트 > OrderService.java
@Autowired
private OrderRepository orderRepository;
@StreamListener(KafkaProcessor.INPUT)
public void onProductOutOfStock(@Payload ProductOutOfStock productOutOfStock) {
try {
if (productOutOfStock.isMe()) {
System.out.println("##### listener : " + productOutOfStock.toJson());
Optional<Order> orderOptional = orderRepository.findById(productOutOfStock.getOrderId());
Order order = orderOptional.get();
order.setState("OrderCancelled");
orderRepository.save(order);
}
} catch (Exception e){
e.printStackTrace();
}
}
-
주문,상품,배송 서비스를 모두 재시작 합니다.
-
재고량이 없을시, ProductOutOfStock 가 발행되고 주문이 취소 되는지 확인 합니다.
-
재고량이 넘치도록 주문을 합니다. (상품ID 1번을 100개 주문)
http localhost:8081/orders productId=1 quantity=100 customerId="1@uengine.org" customerName=“홍길동” customerAddr="서울시"
-
카프카의 consumer 를 조회하여 이벤트가 어떻게 호출 되는지 확인 해 봅니다
-
윈도우
kafka-console-consumer.bat --bootstrap-server http://localhost:9092 --topic eventTopic --from-beginning
-
리눅스
kafka-console-consumer.sh --bootstrap-server http://localhost:9092 --topic eventTopic --from-beginning
{"eventType":"OrderPlaced","timestamp":"20200528152024","stateMessage":"주문이 발생함","productId":1,"orderId":1,"productName":"TV","quantity":100,"price":10000,"customerId":"1@uengine.org","customerName":"“홍길동”","customerAddr":"서울시","me":true}
{"eventType":"ProductOutOfStock","timestamp":"20200528152024","stateMessage":"재고량 바닥","productId":1,"orderId":1,"me":true}
{"eventType":"OrderCancelled","timestamp":"20200528152024","stateMessage":"주문이 취소됨","productId":1,"orderId":1,"productName":"TV","quantity":100,"price":10000,"customerId":"1@uengine.org","customerName":"“홍길동”","me":true}
{"eventType":"ProductChanged","timestamp":"20200528152024","stateMessage":"상품 변경이 발생함","productId":1,"productName":"TV","productPrice":10000,"productStock":110,"imageUrl":"/goods/img/TV.jpg","me":true}
{"eventType":"DeliveryStarted","timestamp":"20200528152024","stateMessage":"배송이 시작됨","deliveryId":1,"orderId":1,"quantity":100,"productId":null,"productName":"TV","customerId":"1@uengine.org","customerName":"“홍길동”","deliveryAddress":"서울시","deliveryState":"DeliveryStarted","me":true}
{"eventType":"DeliveryCancelled","timestamp":"20200528152025","stateMessage":"배송이 취소됨","deliveryId":1,"orderId":1,"quantity":100,"productId":null,"productName":"TV","customerId":"1@uengine.org","customerName":"“홍길동”","deliveryAddress":"서울시","deliveryState":"DeliveryCancelled","me":true}
- 주문을 하였을때 ProductOutOfStock 와 OrderCancelled, DeliveryCancelled 등이 연이어 발생 하는 것을 확인 할 수 있습니다. 추가적으로 ProductOutOfStock 이벤트일때 ProductChanged 가 발행하지 않도록 하는 구현이 추가가 되어야 합니다. 해당 부분은 직접 구현 하여 보시고, 결과는 아래 링크에서 확인 하실 수 있습니다.
ProductService.java
구현 완료시 프로세스 모형